
AI in software development is no longer a pilot conversation in 2026 — it is a standing line item in engineering budgets. The real question on the table for CTOs and engineering managers is narrower and sharper: which tools, at what cost, for which tasks, with what measurable return, and what happens to the team when 40 to 60 percent of diffs start originating from an AI coding agent. This playbook is written for that decision.
The post is deliberately not about shipping AI features to end users. It is about buying, piloting, rolling out and measuring AI tooling for a 10 to 50 engineer team. We cover the current tool landscape, the Model Context Protocol (MCP), agent SDKs for custom internal automation, adoption steps, a DORA-based ROI framework, security posture per vendor, a realistic cost model in USD, and what still belongs in human hands.
The 2026 Landscape of AI-Assisted Engineering
The market has sorted itself into three fairly distinct tiers of capability. Treat them as separate products even when the same vendor sells two of them, because the rollout playbook, the ROI signature and the security review are different in each.
Tier 1: Inline Completion
The original category: ghost text in the editor, single-line or small block completions, trained on public code plus on your codebase as context. Best fit: low-risk productivity on routine code. Representative products: GitHub Copilot (still the biggest installed base), Tabnine (on-prem friendly), Codeium and Windsurf inline, Cursor Tab (notably stronger in 2026 than the legacy Copilot completion model on many languages).
ROI here is incremental and well studied. Vendors will quote 35 to 55 percent productivity uplifts. Independent meta-analyses across 2024 and 2025 converge on a more modest 10 to 20 percent time saved on routine tasks, closer to zero or slightly negative on novel or complex work. Treat the vendor number as marketing.
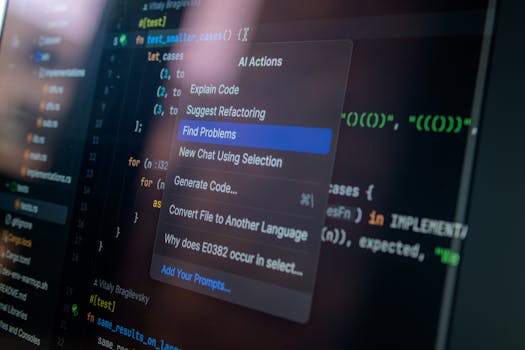
Tier 2: Chat in the IDE
A model with read access to your repo, a conversation thread, and the ability to propose multi-file diffs. The engineer still drives and accepts. Representative products: Cursor, Claude Code (interactive mode), GitHub Copilot Chat, Sourcegraph Cody, JetBrains AI Assistant, Windsurf Cascade, Zed AI. This tier is where most meaningful time savings in 2026 come from — PR scaffolding, test generation, targeted refactors, explaining unfamiliar code, drafting commit messages and release notes.
Tier 3: Autonomous Agents
The agent takes a ticket or a goal and runs a loop: read code, run commands, write code, run tests, open a PR. The human reviews the output, not every step. Representative products: Claude Code agent mode, Devin by Cognition, GitHub Copilot Workspace, Aider, SWE-agent, OpenHands. This tier is the most talked about and the most oversold. It works well on a narrow band of tasks and fails loudly on the others. More on that below.
Tools Worth Shortlisting in 2026
The shortlist below is not exhaustive — it is the set that most US engineering teams of 10 to 50 end up evaluating in a serious RFP. Product tiers and prices quoted in USD.
| Tool | Seat price (USD/mo) | Data handling default | MCP support | Autonomous mode | Best for |
|---|---|---|---|---|---|
| GitHub Copilot Business | $19 per user | No training on your code; audit logs; SSO | Yes (2026) | Copilot Workspace (preview/GA depending on tier) | Teams already on GitHub Enterprise; org-wide admin controls |
| GitHub Copilot Enterprise | $39 per user | ZDR option; private model routing; SOC 2 Type II | Yes, with admin allowlist | Workspace, org-wide agents | Large enterprises with compliance and audit requirements |
| Cursor Business | $40 per user (Pro $20) | Privacy mode; no training on your code; SSO; audit logs | Yes, first-class | Agent mode in IDE | Teams that want the most aggressive in-IDE AI and MCP usage |
| Claude Code | Usage-based via Anthropic API; typical $30-$120/eng/mo | Enterprise ZDR; no training on API traffic | Native (MCP originated here) | Yes, agent mode with Skills and SubAgents | Agent-heavy workflows, custom MCP servers, deep CLI integration |
| Sourcegraph Cody Enterprise | Custom (typical $49-$89 per user) | Self-host or VPC; choose your own LLM; SSO; SOC 2 | Yes | Agentic batch changes | Regulated industries, monorepos, teams that want to bring their own model |
Per-engineer annual budget in 2026 typically lands between $250 and $1,500, depending on seat tier and agent usage. A hybrid model (Copilot seat for everyone plus usage-based Claude Code for heavier users) is increasingly common.
MCP: Why It Matters for Internal Tooling
Model Context Protocol is the most important standard in this space and the easiest one for a CTO to underestimate. MCP is an open protocol, originated by Anthropic and adopted by most major vendors through 2025 and 2026, that lets any MCP-compatible client connect to any MCP-compatible server. Tools and data sources become pluggable.
The practical consequence: instead of every AI assistant reinventing its own GitHub integration, its own Jira integration, its own database connector, you expose each capability once as an MCP server and every assistant your team uses can consume it. Public MCP servers exist for GitHub, GitLab, Jira, Linear, Slack, Notion, Confluence, Postgres, BigQuery, Snowflake, Sentry, Datadog, CloudWatch, PagerDuty, Stripe, and most of the tools a modern engineering org already runs.
The more interesting move is internal. Teams are building custom MCP servers that wrap an internal admin API, an internal observability layer, or a proprietary deploy system. Once that server exists, any engineer in any IDE can ask their assistant to pull production traces, roll back a feature flag, or generate a report from the internal data warehouse. This is where agent productivity compounds. Budget a quarter of engineering AI investment for internal MCP servers if you are serious about leverage.
Agent SDKs for Custom Automation
If MCP is the protocol layer, agent SDKs are the framework layer for building your own in-house agents that do not live in an IDE. Relevant families in 2026: the Claude Agent SDK (the same primitives that power Claude Code, now exposed programmatically in Python and TypeScript), Vercel AI SDK with its agents module, LangGraph (the de facto choice when you need explicit graph-based control), OpenAI Agents SDK, and AutoGen from Microsoft Research.
Typical uses: a nightly agent that triages new Sentry errors and opens draft PRs, a release-notes agent that summarizes merged PRs by product area, a customer-support triage agent that reads tickets and attaches the right playbook. The unit economics here are better than IDE assistants because the work runs unattended and the outputs replace full tasks, not keystrokes.
This post does not go deep on SDK code. If your team is already shipping user-facing LLM features, the relevant companion reads are our guides on React Native with Artificial Intelligence for on-device and cloud AI patterns on cross-platform apps, and how to integrate ChatGPT and generative AI into your app for product-side integration patterns.
Adoption Playbook for a 10 to 50 Engineer Team
The single biggest mistake teams make is buying seats for everyone on day one. Treat AI tool adoption the way you treat any other major tooling change — a deliberate pilot, measured, then expanded. The following five-step playbook is what most successful rollouts look like in 2026.
Step 1: Pilot With 3 to 5 Engineers, One Tool Only, 2 to 4 Weeks
Pick a tight cross-section: one senior, two mid-level, one or two juniors, at most one language family. Buy one tool, not three. Give them 2 to 4 weeks and a weekly 30-minute sync. The goal of the pilot is not to prove ROI — it is to expose the failure modes, the security questions, and the onboarding friction before they hit 40 engineers at once.
Step 2: Baseline Metrics Before Anyone Installs Anything
Capture the four DORA metrics for the pilot group and for a control group of similar seniority over the previous 90 days: deployment frequency, lead time for changes, change failure rate, and mean time to restore (MTTR). Capture PR-level signals too — first-review latency, number of review cycles, revert rate. Run a quick baseline SPACE survey on satisfaction and perceived flow. Without a baseline, the ROI conversation six months from now will be folklore.
Step 3: Measure the Delta and Read Code Quality
At the end of the pilot, compare the same metrics. Two signals matter most: lead time for changes (expect a 10 to 25 percent reduction on routine tickets, little to no change on architecture-heavy work), and change failure rate (watch it like a hawk — if it rises, the tool is generating plausible code that does not actually work, and your reviewers are rubber-stamping). Pull a random sample of 20 AI-assisted PRs and code-review them as an engineering leadership exercise. If the quality is lower than your baseline, the speedup is fake.
Step 4: Broader Rollout With Training and Norms
If the pilot checks out, roll out in waves of 10 to 15 engineers. Ship a one-page internal playbook covering acceptable use, review etiquette for AI-generated diffs, how to disclose AI assistance in a PR description, what never goes into a prompt (customer PII, secrets, vendor confidential terms), and where to file bugs. Pair every wave with a 60-minute live training that focuses on what the tool is bad at, not what it is good at. Engineers discover the good parts on their own.
Step 5: Quarterly ROI Review and Tool Swap if Needed
AI tooling is a market where the leader changes every six to nine months. Lock yourself into a quarterly cadence: pull DORA numbers, survey engineers, reconcile seat cost with measured delta, and be willing to swap. Contracts should reflect this — prefer annual commitments only when you get meaningful discount and still allow seat-level downgrades.
Measuring ROI Honestly
Most public productivity numbers on AI coding are either vendor marketing or academic meta-analyses, and they point in different directions. The honest synthesis for a 2026 CTO: expect 10 to 25 percent improvement in lead time on routine work, much smaller or negative impact on novel/architectural work, and a meaningful reduction in toil that does not always show up in DORA metrics but does show up in engineer satisfaction surveys.
- DORA: deployment frequency, lead time for changes, MTTR, change failure rate. These are the primary outcome metrics.
- SPACE: satisfaction, performance, activity, communication, efficiency — use the subjective parts to catch things DORA misses, especially around flow state and meeting load.
- PR-level: first-review latency, review cycles per PR, revert rate, percent of PRs that required a follow-up fix within 7 days.
- Per-engineer: self-reported time saved per week (with the caveat that engineers systematically over-report this), percent of time in deep work.
Resist the temptation to report a single productivity number to the board. It will be wrong. Report a small panel of metrics, with a baseline and a confidence interval.
Security Posture and Data Handling
The security review is where AI tooling adoption stalls in most enterprises, for defensible reasons. Four questions to answer per vendor, in writing, before the pilot starts:
- Does the vendor train on your code by default? With the major enterprise tiers (Copilot Business and Enterprise, Cursor Business, Claude Code via API, Sourcegraph Cody), the answer is no. Confirm it in the DPA.
- Is Zero Data Retention available? ZDR is offered by Anthropic and OpenAI enterprise tiers and means prompts and completions are not stored after the request completes. Required for regulated workloads.
- Can you self-host or deploy in a VPC? Sourcegraph Cody Enterprise supports self-hosting and bring-your-own-model. GitHub Copilot Enterprise allows private model routing. Tabnine offers on-prem deployments. Useful when data residency or customer contracts require it.
- What controls do admins have? SOC 2 Type II, SSO/SAML, audit logs, content-filtering policies, per-repo allowlists, telemetry opt-outs. The answer should be yes to all of these or the vendor is not enterprise-ready.
Every AI call also crosses a prompt-injection boundary. Assume that any document the agent reads could contain hostile instructions. Never grant an agent write access to production systems without a human approval step, and never let it execute shell commands on a production host.
Risks and Limits Nobody Is Advertising
- Over-reliance among juniors. Engineers early in their career ramp noticeably slower if they accept completions without reading the surrounding code. Deliberate friction helps: require juniors to write the first draft, use AI only for review and refactor.
- Hallucinated APIs and libraries. Models fabricate plausible function names, invent package versions, or recommend deprecated patterns. Caught easily by tests and by a sharp reviewer; missed by a tired one.
- Security blind spots. AI-suggested code reproduces known bad patterns (weak crypto defaults, SQL string concatenation, missing authz checks). Pair adoption with a stricter linter and secret-scanning pipeline.
- Vendor lock-in. Proprietary agent formats, private MCP extensions, and workflow-specific automations create switching cost. MCP mitigates this — prefer vendors that adopt it natively.
- Cost creep on usage-based billing. A single engineer running agent loops overnight can burn through a sizable budget. Set per-user caps and alerts from week one.
- PR bloat. Agents generate more code per ticket than humans. Large diffs get reviewed more superficially. Enforce a size budget per PR and push back when diffs balloon.
- Silent model version shifts. Vendors update underlying models without notice. Behavior that worked last week may not this week. Pin versions where supported and track model-change advisories.
Autonomous Agent Workflows That Actually Work in 2026
Where agents deliver today, based on consensus across reports from Microsoft, GitHub, Google, and several US startups:
- Bug triage and reproduction: agent pulls logs, reproduces locally, proposes a fix.
- Dependency upgrades: framework minor versions, transitive security patches, typed across many files.
- Small refactors spanning many files: rename, adapter introduction, style migration.
- API migration (your service adapts to a new upstream version).
- Documentation drift repair.
- Test generation for existing code with known behavior.
Where agents still fail more often than they succeed: cross-module business logic, security-critical code paths, systems the agent has no context on, performance work, any task that requires talking to a human to disambiguate requirements. Keep these on the human side for 2026.
CI/CD Integration
AI is increasingly pulled into the pipeline itself, not just the editor. The stack worth knowing:
- AI code review bots: GitHub Copilot review, CodeRabbit, Greptile, Diamond by Graphite. They catch a slice of mechanical issues before human review.
- AI release notes and PR summaries: most major Git hosts now offer this natively.
- AI test generation: best used as a starting point for property-based or regression tests; requires human sanity checks.
- AI flakiness detection: pattern-matches flaky tests across runs; Lightrun, Trunk and others ship this.
- AI security review: Semgrep AI, Snyk Code AI, GitHub Advanced Security — complementary to traditional SAST, not a replacement.
Team Culture: What Changes When Agents Write 40 Percent of Your Code
The most underappreciated impact of AI coding is cultural. Pairing is redefined: the agent is a third presence in the session, and senior engineers have to learn when to ignore it. Review etiquette changes: reviewers develop a smell for AI-generated slop (plausible boilerplate that does not match the ticket, over-commented code, tests that only cover the happy path). Promotion and performance processes need to shift away from raw output volume toward judgment, code quality, and cross-team impact — otherwise you will accidentally promote whoever ran the most agent loops.
Code ownership becomes awkward when an agent wrote 60 percent of a PR and a human merged it. The working convention in 2026 is that the human reviewer/merger owns the code. If the agent wrote something wrong and it shipped, that is on the human who approved it. That rule is worth writing down in your engineering handbook.
What Stays Human in 2026
Teams that are winning with AI tooling draw an explicit line around what humans still own: architecture decisions, security review of sensitive code paths, product tradeoffs, stakeholder communication, on-call judgment calls during incidents, customer data handling decisions, tech debt prioritization, and the final call on what gets shipped. Agents are excellent at implementing a decision. They are not the ones making it.
Working With a Nearshore Partner That Already Uses This Playbook
If you are a US company and your internal team does not yet have the bandwidth to run this adoption cycle end to end, a good nearshore partner can close the gap. At FWC Tecnologia, our engineers already work with this toolchain daily — Claude Code in the terminal, Cursor in the IDE, custom MCP servers for our internal systems, Copilot in Git workflows — and we embed those practices into the client engagements we run from Brazil. The time-zone overlap with US business hours is 1 to 3 hours and the cost savings versus US on-shore rates land in the 30 to 60 percent range, which is the context most US buyers care about.
Before you hire anyone, inside or outside the US, our short guide on 10 questions to ask before hiring a software development company is a useful filter. The deeper buyer material lives in the custom software development guide for US companies and the nearshore AI development company vetting guide. If nearshoring to Brazil specifically is on your shortlist, the IT outsourcing to Brazil complete guide covers the contracting and timezone mechanics.
Closing: Treat AI in Software Development as a Budget Line, Not a Project
The single most useful frame a CTO can adopt in 2026 is this: AI in software development is no longer a project to evaluate — it is a recurring budget line to manage, like cloud or observability. Pilot deliberately, measure with DORA plus PR-level signals plus honest engineer surveys, set the security posture in writing, cap per-engineer cost, revisit quarterly. The teams that win with AI coding agents are not the ones that adopted fastest; they are the ones that adopted with the most discipline.
If you want a second opinion on your adoption plan, or an engineering team that already runs this playbook from day one, get in touch with our team or request a project scoping.